CVSS 4.0 Released: The king is dead, long live the king!
by Peter Magnusson 2023-11-10
Common Vulnerability Scoring System CVSS 4.0 has been released, with new ways of scoring vulnerabilities. This is the first major release since CVSS 3.0 in 2015, which received a minor update in 2019.
In this blog post I aim to highlight what's new in CVSS 4.0, what's the good and the bad with CVSS and compare it to some alternative vulnerability scoring strategies.
TL;DR: What are the big news in CVSS 4.0?
- Base Metric: Attack Requirements (AT) is added, making a clear distinction between Attack Complexity (AC) and AT.
- Base Metric: Subsequent System (CIA triad) is added, Scope is removed.
- Base Metric: User Interaction is clarified.
- Supplemental Metric is added. Safety, Value Density and various other softer factors.
Let's dive deeper into the changes of CVSS 4.0!
Table of Contents
- Base Metric changes
- Supplemental Metrics
- Problems that CVSS 4.0 does not solve
- Good stuff with CVSS in general
- CVSS alternatives
- The end..?
Base Metric changes
Attack Requirements
With CVSS 4.0, we get a really nice split between preconditions for attack.
CVSS version 3.1 had only Attack Complexity (AC), and there were cases where scorers could disagree. For example, if a system only was vulnerable if a specific configuration option was enabled, should AC be set or not? With CVSS 4.0, this becomes much clearer: AC is now split into two well-defined metrics Attack Complexity (AC) and Attack Requirements (AT).
Attack Requirements (AT) covers deployment and execution specifics necessary for an attack, that are not security attack prevention technologies:
- If a race condition is needed, or
- If a non-default option needs to be enabled; great excerpt from the CVE-2022-41741 example: "NGINX must be built with the module, and configuration must be present. Neither of those are default scenarios for an NGINX OSS web server. The attacker must place a file within the web root and cause NGINX to serve that file."
Attack Complexity (AC) remains but covers only security enhancing conditions such as anti-exploitation technologies:
- Address space randomization (ASLR): a randomized memory space needs to be overcome by e.g. an information leak, multiple attempts, or extensive control over the memory layout from JavaScript.
- Data execution prevention (DEP): stack etc. is non-executable, and attacker needs more advanced techniques like return oriented programming.
- Cryptographic secrets, stack cookies, etc: attacker must obtain or bruteforce a secret value before attack can succeed.
Subsequent System Impact Metrics: SC, SI, SA
Subsequent System Impact metrics largely replace the previous "Scope" metric. These metrics covers impact to subsequent systems, i.e. secondary or third party systems.
Subsequent System Confidentiality (SC) Impact Metric: SC covers confidentiality impact to subsequent systems. Example: attack against a vulnerable component releases a secret that degrades security of another system.
Subsequent System Integrity (SI) Impact Metric: SI covers loss of data trustworthiness to subsequent systems. Example: Cross-Site Scripting attacks are now considered to have no impact to the Vulnerable System, instead SI and SC metrics are affected. The reasoning is that the vulnerable web server is not affected, but the web browser data is affected. i.e. a web browser and its systems is an example of a Subsequent System.
Subsequent System Availability (SA) Impact Metric: cover cases where availability of secondary systems are affected. Example: ARP spoofing attack against a router, in which the router stops operating, resulting in packet loss. Another example: attacks against a web server resulting in databases or file servers being filled up, crashing the subsequent system.
Potential problems and disagreements regarding Subsequent System Impact Metrics
When I look through example vulnerabilities, Subsequent System Impact Metrics largely makes sense. But: there seem to be many cases where scorers will disagree on how to work with Subsequent Metrics. There can easily be disagreements on how to score!
One potential problem is in the documentation: "For example, an attacker steals the administrator's password, or private encryption keys of a web server." That text is about the assets stored on a system, and on a very detailed level.
Let's say we have a vulnerability where we compromise something serious on a file server, for example Microsoft AD credentials. I can see scorers disagreeing like crazy regarding whether compromised credentials even belong in the base metric; it is not part of the vulnerability, it is about you putting sensitive data on a vulnerable server.
- This information is often not known Base Metric level.
- Common scoring providers like NIST National Vulnerability Database NVD and their associated CVE Numbering Authorities (CNA) often do not know what you store in your data stores. These scoring authorities will have to put in their best guess, either High, Low or None.
- Penetration testers with detailed knowledge could know the problem to be High.
- Penetration tester A may want to put this specific knowledge into their Base Metrics.
- Penetration tester B may argue that this better knowledge actually belongs in Environmental Metrics group.
- Penetration tester C may argue B is technically correct, but since we have agreed to only work with Base Metrics we need to make a dirty compromise.
- Penetration tester D may argue that we should have one finding on the generic well known vulnerability (CVE) and another finding on the exposed data.
- Penetration testers may not know impact.
- Especially in short, hurried tests, understanding the Vulnerable System might be hard enough. Understanding all Subsequent Systems might be impossible.
- Lets say file
RSA.KEYis compromised, but during the test its never made clear what the file does. So the penetration tester knows the truth to be "Unknown", we just do not know. There are hours left on the report and the customer does not respond quickly to questions. Your options are High, Low or None, make your best guess on limited knowledge.
So, scoring this correctly will be hard. Another thing is that in many applications it changes what data the system stores. So the same vulnerability / bug could be Low, then High, then None.
To deal with this well, you would need to have a risk owner who is great at owning Environmental Metrics / Modified Base Metrics. I just have a feeling organizations being great at actively working with / updating Environmental Metrics are like pink unicorns with wings and dragon breath. i.e. you will see a lot more flying pigs than you will see organizations able to do this.
Supplemental Metrics
Warning, fancy word ahead:
A new, optional metric group called the Supplemental metric group provides new metrics that describe and measure additional extrinsic attributes of a vulnerability.
These option metrics cover:
- Safety (S) - "Exploiting a vulnerability within that system may have Safety impact"
- Automatable (AU) - "Can an attacker automate exploitation events for this vulnerability across multiple targets?"
- Provider Urgency (U) - "Many vendors currently provide supplemental severity ratings to consumers via product security advisories" (Not defined, Red, Amber, Green, Clear).
- Recovery (R) - How hard it is to recover from exploitation.
- Value Density (V) - Business impact, how much resources / money the attacker gains from a single attack.
- Vulnerability Response Effort (RE) - how hard it is to respond to a vulnerability.
These metrics do answer some questions I imagine that certain customers are asking for. For example, the automotive industry likes to prioritize / tag / tie security as having Safety impact to improve organization / industry response.
Problems that CVSS 4.0 does not solve
CVSS is still borderline broken for Libraries, Client, and Utility software
CVSS 4.0 does little to remedy where CVSS has been working bad when applied, and that is:
- Library software; i.e. someone is scoring something that is not an application.
- Client and Utility software; i.e. major aspects of how the application will be used is unknown / user dependent / configuration dependent.
Daniel Stenberg of cURL fame released a very annoyed and funny blog post: CVE-2020-19909 is everything that is wrong with CVEs, in where the following is discussed:
- An arguably insignificant vulnerability was scored 9.8 Critical (using CVSS 3.1).
- The vulnerability was revised later (NIST 9/05/2023) in several metrics:
- Attack Vector (AV) - which now is considered Local.
- Privileges Required (PR) - which now is considered Low.
- Confidentiality - which now is considered None.
- Integrity - which now is considered None.
- The vulnerability was revised to 3.3 Low after these changes.
Maybe that CVE was a hilarious mishap and never should have been released with the wild score.
But: utilities like curl and libraries like log4j etc are ripe for bad CVSS ratings.
One reason is that CVSS Attack Vector (AV) and other parameters are problematic:
- Server (Network daemons): the CVSS Attack Vector is well defined. It is usually Network. Sometimes it is mitigated to Adjacent by default configuration (or customer specific firewall rules or similar).
- Client software like curl: it is the user who decides what to talk to. I.e. there is a human who decides if Attack Vector is Local, Adjacent or Network.
- Library software like log4j: it is often unknown what the vector is. Unless you know how the software is used downstream, it could be none (there is no real vulnerability), or Local, or Adjacent or Network.
If we look at how this has typically been handled, we can look at Log4j CVE-2021-44228, scored 10.0.
- Attack Vector (AV) was set to Network. Why? Well we do not know the vector and the flaw could be network exposed.
- Confidentiality Impact (CI) was set to High. Why? Well we do not know the impact at library level, so NVD put in High as a guess.
Basically there are whole classes of software where CVSS scoring vulnerabilities is hard.
Could CVSS improve here, is there anything that could be done in a future CVSS revision? Maybe.
- CVSS could advise against scoring vulnerabilities with unknown parameters.
- CVSS could advise against scoring vulnerabilities at library level. If the vulnerability only exists when implemented in an application, and several parameters could differ between implementing applications, should they share CVSS rating?
- CVSS could introduce some "Unknown" option to e.g. Attack Vector (AV), so there would be some unified way of handling "this value is unknown at this level". Not sure how it would affect score derived, but the scores would be a lot more honest.
- Utilization of multiple CVSS scores could be utilized. In NIST National Vulnerability Database NVD you sometimes see multiple scoring providers (CVE Numbering Authorities CNAs), for example Red Hat or Google providing alternative ratings. Whilst not explicitly stated, when I see Red Hat providing different scores than NVD, I presume this means "In the context of Red Hat products, this is the more correct score". This makes a lot of sense, some utility vulnerability could be nonsense to most systems, but be in a critical path for an operating system or cloud vendor. I.e. if things are different the scoring should be different.
CVSS just gets bigger and bigger
CVSS number of metrics is steadily increasing, and 4.0 marks a big jump in size:
- CVSS 1.0 has 7 metrics included in base metrics.
- CVSS 3.1 has 8 metrics included in base metrics.
- CVSS 4.0 has 11 metrics included in base metrics and adds even more optional metrics.
Now, if your work is to score a single vulnerability: this is not an issue.
If you are working on a big report where the customer wants CVSS 4.0, this is an issue.
- The customer does not want you to spend a lot of time on this, the customer just wants correct scores with no work.
- The penetration tester performing the scoring does not want to spend too much time on this.
- "do it correct but fast" 😸
How much would it cost to actually score CVSS 4.0 really well? Hopefully my math is correct here:
- If you have 11 metrics per finding and 60 findings:
- You have have 660 metrics to score.
- If you need 3 minutes per metric to be certain of doing a great job, having thought everything through clearly:
- You have 1980 minutes (33 hours or about 4 days assuming you work 8 hours a day) of scoring to do.
You certainly do not have this time. Maybe this math is a bit exaggerated, slightly straw man argument. But the point: actually spending time on doing CVSS well will quickly start costing a lot of time.
What will likely happen instead:
- You speed run and set the parameters quickly based on experience and a quick take on the vulnerabilities.
- Maybe you only score one vulnerability from each vulnerability class to the best of your abilities. Then you copy-paste your score to all similar / equivalent vulnerabilities in the same report.
- You borrow from NIST National Vulnerability Database NVD rating if they have already scored the same vulnerability.
- Or, you borrow from CVSS 4.0 examples:
- A FIRST example says Reflected Cross Site Scripting is CVSS:4.0/AV:N/AC:L/AT:N/PR:N/UI:A/VC:N/VI:N/VA:N/SC:L/SI:L/SA:N.
- Maybe you trust FIRST and just copy their example. "I trust the authority!"
- But is really everything the same between your vulnerability and the example vulnerability?
So, in a big report there may be a lot of copy-pasting to get scoring down to acceptable times.
And hopefully you and your colleagues are sharp enough to say "Stop wait, this vulnerability is scored wrong". Identify flaws in your scoring before delivery:
- Maybe some vulnerabilities should be scored differently compared to others. Something is different that should be reflected.
- Maybe one reflected Cross Site Scripting vulnerability only happens on an error page that occurs randomly when the server is under load; this means there are Attack Requirements (AT) which are not fully under the attacker's control.
So, for CVSS we have this dilemma:
- To improve scoring accuracy, CVSS evolves into a more and more complex system. CVSS 4.0 reflects this.
- The bigger and more complex CVSS becomes, the more mistakes and copy-pasting you will see.
Chained vulnerabilities
CVSS typically scores vulnerabilities independently.
Attackers often build exploit chains that jump through multiple layers using multiple exploits. 3 medium vulnerabilities could chain together into a high or critical exploit chain.
CVSS risk ratings will therefore often miss the attacker's perspective, in which each vulnerability is an attack primitive, not necessarily the end goal.
Edit 2023-11-22:
- After publication, my colleague pointed out that 3.6 Vulnerability Chaining does cover this topic for a simple 2-step chain.
- Vulnerability A
- CVSS:4.0/AV:L/AC:L/AT:N/PR:L/UI:N/VC:H/VI:H/VA:H/SC:N/SI:N/SA:N
- It requires a local, low-privileged user in order to exploit.
- Vulnerability B
- CVSS:4.0/AV:N/AC:L/AT:N/PR:N/UI:P/VC:L/VI:L/VA:L/SC:N/SI:N/SA:N
- It provides an unprivileged, remote attacker the ability to execute code on a system with Low impacts if a local user interacts to complete the attack.
- How to combine: Given A and B, Chain C could be described as the chain of B → A, CVSS:4.0/AV:N/AC:L/AT:N/PR:N/UI:P/VC:H/VI:H/VA:H/SC:N/SI:N/SA:N which combines the Exploitability of B, and the Impact of A
i.e. arguably CVSS 4.0 standardizes how to deal with simple, obvious, vulnerability chains. And it is up to implementers if they want to score chains.
Good stuff with CVSS in general
What are the really good things with CVSS? Why is this system so popular?
CVSS is the king of good documentation and examples
Within the field of common, clinical, analytical approaches to scoring, CVSS is king.
CVSS 4.0 provides several detailed examples of how CVSS scoring should be applied. So if you wonder "how should I score something like this?" you can look for similar examples in case the documentation isn't clear enough.
Clarity of responsibility
My colleague loved this text:
The application of Environmental and Threat metrics is the responsibility of the CVSS consumer. Assessment providers such as product maintainers and other public/private entities such as the National Vulnerability Database (NVD) typically provide only the Base Scores enumerated as CVSS-B.
There are good reasons for trying to stay away from Environmental and Temporal metrics;
- They are constantly subject to change.
- Penetration test reports are often consumed long after they were written.
- Environmental or Temporal metrics should in my humble option only be handled in very active organizations, which somehow have the ability to keep them updated.
CVSS alternatives
OWASP Risk Rating: Informal Method
OWASP Risk Rating: Informal Method is a mix between "Run with your gut feeling" and "Apply some science/math".
You assign Low, Medium, High based on your best guess to Likelihood and Impact.
Then you score total risk according to a matrix, as detailed in the figure below:
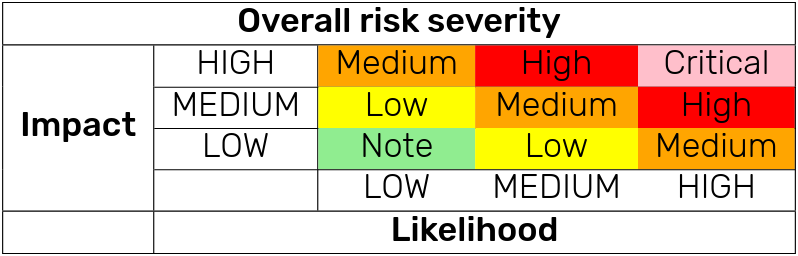
So very quick and easy.
Arguably this system is extremely driven by how the scorer feels, reasons, their experience and gut feeling.
Also there is no clear threshold for Critical. If both factors are High, result is Critical.
If you compare to CVSS, Apache or Microsoft Bug Bars, this is very interesting. The other methods usually has some clear condition that prevents something being considered Critical.
- In CVSS 4.0, a remote code execution bug becomes downgraded to 8.7 if only exposed to Adjacent networks, or 8.7 if Privileges Required (PR).
- In Apache, specific language defines several criteria necessary to be considered Critical: "This rating is given to flaws that could be easily exploited by a remote unauthenticated attacker and lead to system compromise (arbitrary code execution) without requiring user interaction. Flaws that require authentication, local or physical access to a system, or an unlikely configuration are not classified as Critical."
- In Microsoft Bug Bars, you typically have similar criteria like those outlined by Apache.
Essentially, OWASP Risk Rating, in my humble opinion, will generate more Critical because it lacks stopping criteria. "High X High equals Critical" simply generates more Critical than other methods.
OWASP Risk Rating: Repeatable Method
OWASP Risk Rating: Repeatable Method and CVSS are kind of doing almost the same thing. But very differently.
Both methods fundamentally reflect the belief that there exists a formula to measure risk, that if you only can describe a threat in enough detail you will get a scientifically correct risk.
I personally argue that for many applications CVSS is superior, and far more repeatable:
CVSS Base Metrics tries to measure:
- Exploitability. How exploitable is a vulnerability based on specifics about the vulnerability.
- Impact Metrics. Based on a CIA triad.
OWASP Risk rating tries to measure almost the same thing, but:
- Likelihood Factors
- Threat Agent factors focuses on "who can attack the system", i.e. threat agent assessment.
- Vulnerability factors focuses on "how easy is the vulnerability to find", i.e. kind of the same thing as CVSS Exploitability, but actually also completely different.
- Impact Factors
- Technical Impact Factors: same thing as CVSS Impact factors.
- Business Impact Factors: customer specific business impact analysis.
- Likelihood Factors
If you think about this carefully, you will start to see the greatness of why CVSS has a base metric is so different. But if you think too much about the OWASP Risk Rating details, you will go insane.
There is no Base Score or Base Metrics in OWASP Risk Rating. The factors are not stable of time or environments.
Threat Agent Factors and Vulnerability Factors are extremely interlinked. Them being two independent set of metrics is insanity.
- Lets say no public exploit exists for an unknown, hard to exploit vulnerability that is remotely accessible over the Internet.
- Basically all Vulnerability Factors indicate this is hard to find and exploit.
- Threat Agent factors indicate that only very skilled attackers can attack.
- Lets say a public exploit is released, along with way of finding targets; e.g. a scanner, google dork, Shodan search.
- Vulnerability Factors now indicate the vulnerability is super easy to find and exploit.
- Threat Agent Factors now indicate that almost everyone can exploit the vulnerability.
- Lets say no public exploit exists for an unknown, hard to exploit vulnerability that is remotely accessible over the Internet.
Vulnerability Factors may change just by me writing my penetration test report.
- Awareness goes up. Lets say it is Unknown until I found it, once my report is disseminated to teams to fix, it is at best Hidden.
- Ease of exploit goes up if I document it well.
- If I deliver a text saying "something something about X is vulnerable", that does not help anyone much. The problem will never be prioritized.
- If I deliver an example of me actually exploiting the vulnerability, or command-line output giving fixers a good idea about how exploitable it is. Defenders (and attackers) can understand the gist of a well documented finding. If you have a good report, you likely can reverse engineer a fully working attack / proof of concept from the report. We have increased exploitability just by documenting the finding well. So by writing a good report we could change Ease of exploit from N/A (or Theoretical) to Easy.
Threat Agent has its own set of funny problems:
- Same vulnerability likely has multiple threat agents. If your methodology tries to provide a single score, ignoring that you have multiple threat actors and therefor multiple scores, you are clearly doing things wrong.
- Unless someone is spending time on threat agent research, you often do not know who the attackers are.
- In the context of a normal penetration test report, trying to deal with this is hard.
Business Impact Factors is also arguably a problem, in terms of how security test scoring often is performed.
- Business people are typically not present when scoring vulnerabilities / security findings.
- Technical people like penetration testers or product security staff typically enter this, which is not part of their domain knowledge. So this is typically filled in by people without business expertise.
So, at least to my eyes, OWASP Risk Rating Repeatable methods has a lot more problems than CVSS.
Old-school Gut feeling system
Back in the old days (1990's and earlier), we had the "gut feeling" system where you looked at a vulnerability and assigned the severity which made sense. A vulnerability was rated critical if it was critical.
Everything was easy, everyone happy (unless we disagreed, and just got angry with each other).
One dirty secret is that most scorers still apply the gut feeling system to some extent.
- If you score a vulnerability using e.g. CVSS and the result makes sense, you are happy and done.
- If your score disagrees with your professional experience: you start checking if anything is wrong, if any metric could be modified to get a more correct result.
- In many systems, it is not black and white. If the score is too high, maybe you double / triple check Attack Complexity (AC), Attack Requirements (AT) or similar.
Vendor Rating systems, Bug bars (Apache, Microsoft and others)
Apache, Microsoft and other vendors formalized the concept of rolling your but well defined scoring system.
Especially within Microsoft SDL it was recognized that not all products are equal. What is a severe vulnerability in Microsoft Word may be very different from what is a severe vulnerability in Microsoft Windows. By making a product unique bug bar based on good product and threat understanding, you can deliver a rating that better reflects the threat to a user.
- Apache vulnerability severity rating system
- Microsoft Security Development Lifecycle SDL
- Microsoft Vulnerability Severity Classification for Windows
Exploit Prediction Scoring System
Exploit Prediction Scoring System EPSS collects a large set of metadata about vulnerabilities. Based on statistical methods derived from past incidents and current knowledge about the vulnerability, it calculates a prediction of how likely the vulnerability is to be exploited.
This is not something easily utilized when writing penetration test reports. You need all the metadata, and the entire model, but it's definitely something to consider if you are a defender and feel you need help prioritizing.
The end..?
Thank you for reading! If you have any comments, questions or if you are interested in vulnerability scoring and management in general, please contact us!